Pseudo-standard Text File Adoption Rates (2019)
Published
How many sites use {robots,humans,security}.txt files?
That’s the question I wanted to answer.
I got curious about the usage & adoption of pseudo-standard text files & wanted to see what it looked like with popular websites. To be clear, by pseudo-standard text files I’m talking about robots.txt, humans.txt, and security.txt. They’re “pseudo-standards” because none of them exist as an official RFC, just various stages of drafts or non-standards. A quick overview of the three:
robots.txt
Likely the most familiar, a robots.txt file serves the purpose of telling web crawlers what content should / shouldn’t be indexed or where a sitemap is located. It exists as an Internet-Draft from 1996, making it the oldest of the trio.
humans.txt
Of the three, humans.txt is the most non-standard free-form, which is by design. It exists to credit the authors & everyone behind the scenes of website, meaning you can put anything in it. For example, check out my humans.txt from my personal site.
security.txt
This is the newest of the three, with the latest Internet-Draft released earlier this year. The security.txt file exists with the purpose to “help organizations define the process for security researchers to disclose security vulnerabilities securely1.”
Methodology
To get the data, I wrote a script in Node.js. If you’re curious, it’s available on GitHub. Node.js works well with it’s asynchronous non-blocking I/O nature. Memory usage was a limiting factor — 25,000 domains proved to be the upper bound — even after letting V8 munch on more RAM2. It would be interesting to look at optimization strategies.
I went with an extremely simple data structure for the domains to be crawled: a plain-text file with one domain per line (loaded into an Array in Node.js). I was able to find a dataset of Alexa.com top 1-million sites off Kaggle to use. Copy-pasting rows from the CSV into a text file proved to be trivial.
For crawling the files, I did basic checks for the HTTP status code, the right Content-Type, and the first few values of the actual file. That’s detailed more on GitHub & the source code, if you’re curious. Finally, any valid-looking files are written to the filesystem. After it’s all done (or I Ctrl + C the process) the metrics are printed to stdout.
Results
Before digging into the results, a few issues regarding the completeness & accuracy of the data:
- For certain domains, like Google & the Stack Exchange network, there are a heap of “duplicate” files. For the sake of this analysis, I strictly care about if a file is found for a domain, not if it’s unique within the entire results.
- Redirects aren’t always handled with grace, which impacts my results. For the analysis, I fire off requests to the
http://domain, with the hope that any HTTPS upgrades & redirects are handled appropriately (I handle up to 20 redirects). Sometimes there’s inconsistencies with the apex & www subdomain, I can’t do much about that.- Example of poorly-handled redirects:
- http://youtube.com/robots.txt
404s instead of: - redirecting (
301) to https://youtube.com/robots.txt and then finally: - redirect (
301) to http://www.youtube.com/robots.txt. - That’s how it’s handled for the
/path, it would make sense to do the same for/robots.txt.
- Not all requests receive a response. I used my judgment to let the script run for a while3 before terminating in those instances.
That said, let’s take a look at the results:
| domains | robots.txt | humans.txt | security.txt |
|---|---|---|---|
| 5 (FAANG) | 100% (5) | 40% (2) | 40% (2) |
| 100 | 83% (83) | 16% (16) | 16% (16) |
| 1,000 | 79.2% (792) | 8.3% (83) | 7.2% (72) |
| 10,000 | 72.75% (7275) | 3.03% (303) | 1.73% (173) |
| 25,000 | 70.58% (17644) | 1.96% (489) | 1.08% (271) |
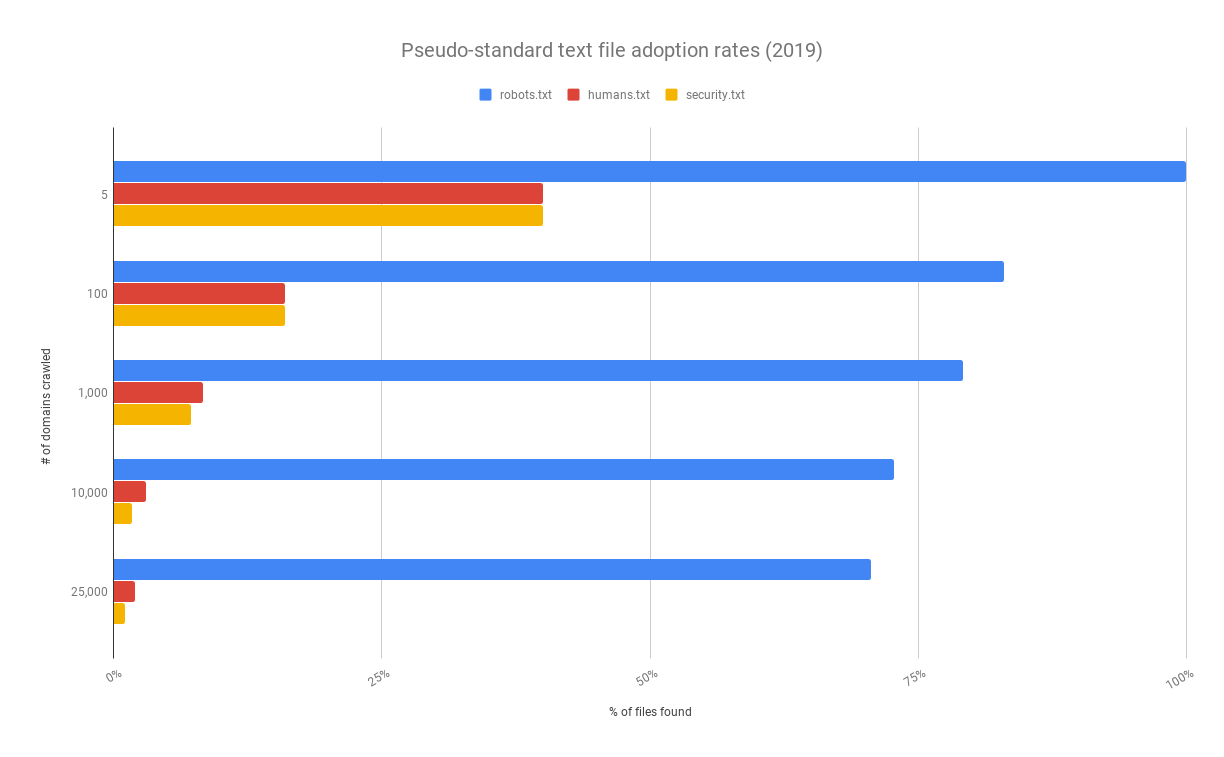 Results plotted in a stacked bar chart
Results plotted in a stacked bar chart
Findings
Before starting this analysis, I made a prediction:
 My initial prediction for the results
My initial prediction for the results
Based on the results, I wasn’t completely off. I was surprised to find humans.txt & security.txt to be so close — since security.txt is much newer. Further, I was surprised to see robots.txt drop off (below 3/4) for more than 1,000 domains.
In the process of fine-tuning my analysis process, I manually peeked at all the humans.txt files I found. Cool findings from that included impressive ASCII art, emojis (the modern web is wild like that), easter eggs, clever jokes, and subtle additions like namespaced contact emails (hi+humans@domain.tld).
With that, I’ll leave you with my 100% non-exhaustive list of cool humans:
- https://disqus.com/humans.txt
- https://foursquare.com/humans.txt
- https://www.free.fr/humans.txt
- https://healthunlocked.com/humans.txt
- https://massdrop.com/humans.txt
- https://medium.com/humans.txt
- https://monday.com/humans.txt
- https://nos.nl/humans.txt
- https://www.php.net/humans.txt
- https://player.fm/humans.txt
- https://stripe.com/humans.txt
- https://teespring.com/humans.txt
- https://tinypng.com/humans.txt
- https://www.000webhost.com/humans.txt
- http://www.adultswim.com/humans.txt
- https://www.dn.se/humans.txt
- https://www.expensify.com/humans.txt
- https://www.symantec.com/humans.txt
- https://www.tumblr.com/humans.txt
- https://www.vogue.co.uk/humans.txt
- https://dbrand.com/humans.txt
- https://nebenan.de/humans.txt
- https://www.piliapp.com/humans.txt
- https://seranking.com/humans.txt
- https://ss64.com/humans.txt
- https://www.750g.com/humans.txt
- https://www.artsy.net/humans.txt
- https://www.checkout.com/humans.txt
- https://www.limeroad.com/humans.txt
- https://www.onshape.com/humans.txt
- http://www.pb.com/humans.txt
- https://www.zazzle.com/humans.txt
Verbatim from https://securitytxt.org/↩︎
--max-old-space-sizewas my friend↩︎2.5 hours for the 25k domains run↩︎
I love hearing from readers so please feel free to reach out.